[HT.V0.1.1]Automatic spacing corrector
 Demo
Demo
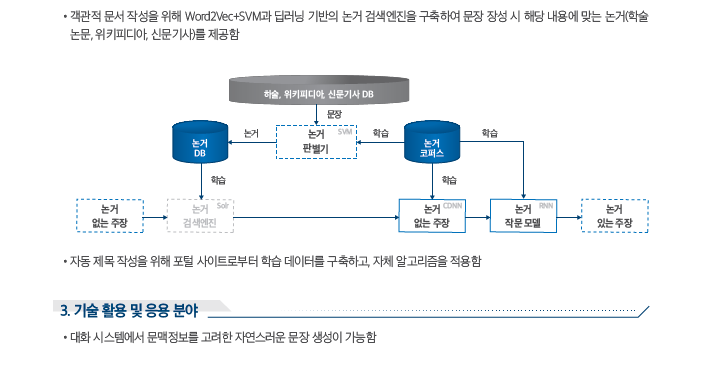
In Korean, spaces are very important to improve the readability of the sentence and to convey the meaning of the sentence accurately. Automatic word-separation system
The system restores the line boundaries of a document recognized by the character recognition engine, the preprocessor of Stemmer, which is the most basic application system of natural language processing.
An important role as a post-processor, a post-processor that correctly divides continuous syllable sentences generated from speech recognition, and a spell checker module.

[HT.V0.1.2]Morphological analysis technology
Demo

[HT.V0.1.3]Korean Morphological Analyzer
Demo

[HT.V0.1.4]Named Entity Recognition
Demo

[HT.V0.1.5]Automatic character classification technology
Demo

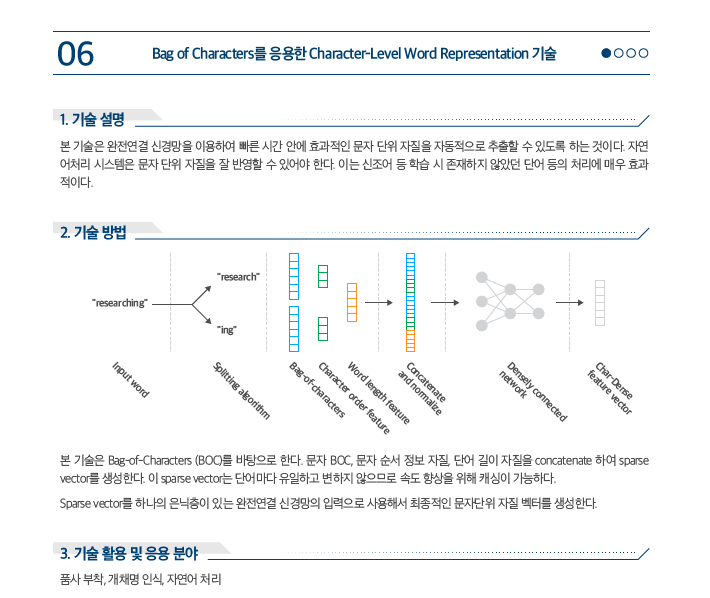
[HT.V0.1.6]Character-Level Presentation Technology with Bag of Characters
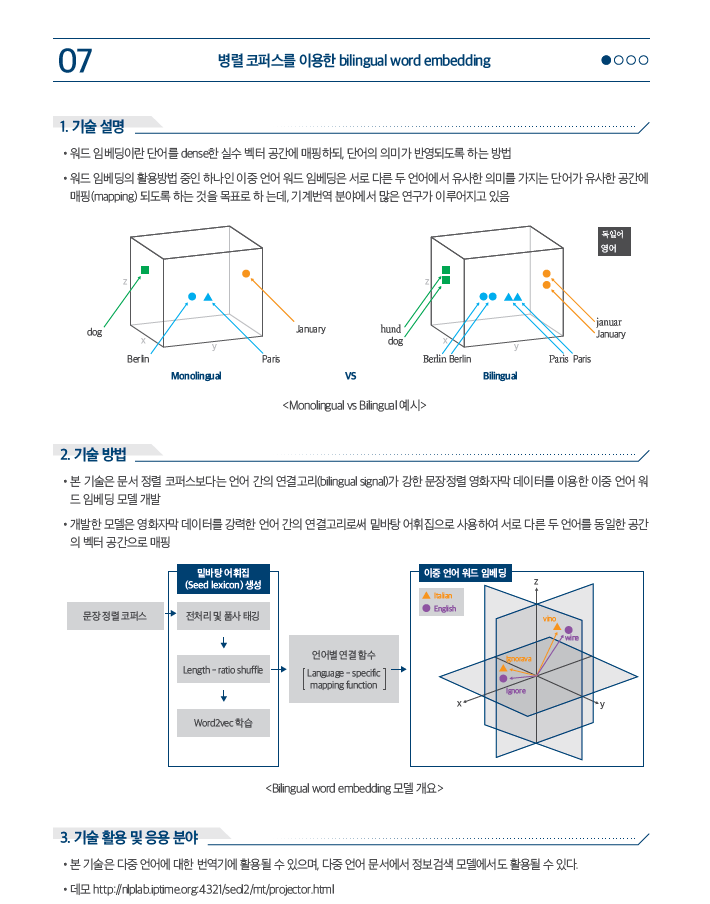
[HT.V0.1.7]bilingual word Embedding with parallel coppers
Demo
[HT.V0.1.8]Parsing Dependent on Korean Language Using Stack-Pointer Network
Demo

[HT.V0.1.9]Dependency Parser
Demo

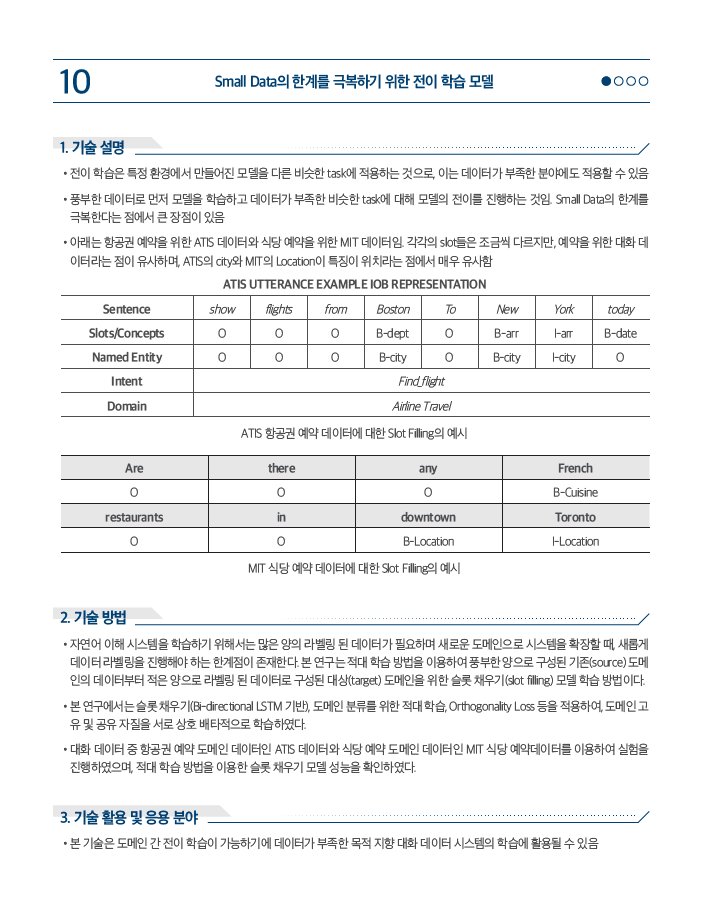
[HT.V0.1.10]Transition Learning Model to Overcome Small Data Limits
[HT.V0.1.11]Statistical-Based Korean News Emotional Analysis
Demo

[HT.V0.1.12]Cross-Validation Ensemble Technique in Natural Language Inference

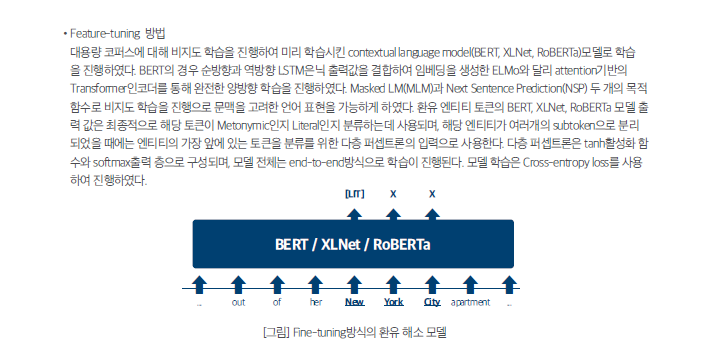
[HT.V0.1.13]Metonymy solution using deep learning method

[HT.V0.1.14]Denoising Transformer-Based Korean Spelling Correctional Technique
Demo

[HT.V0.1.15]Resolving word meaning ambiguity using knowledge embedding deep learning

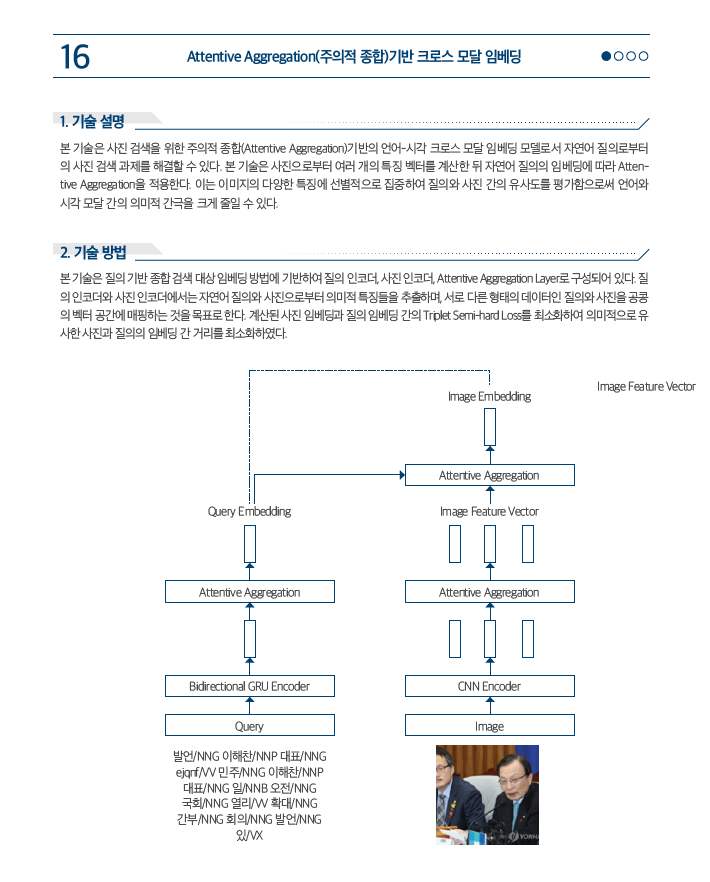
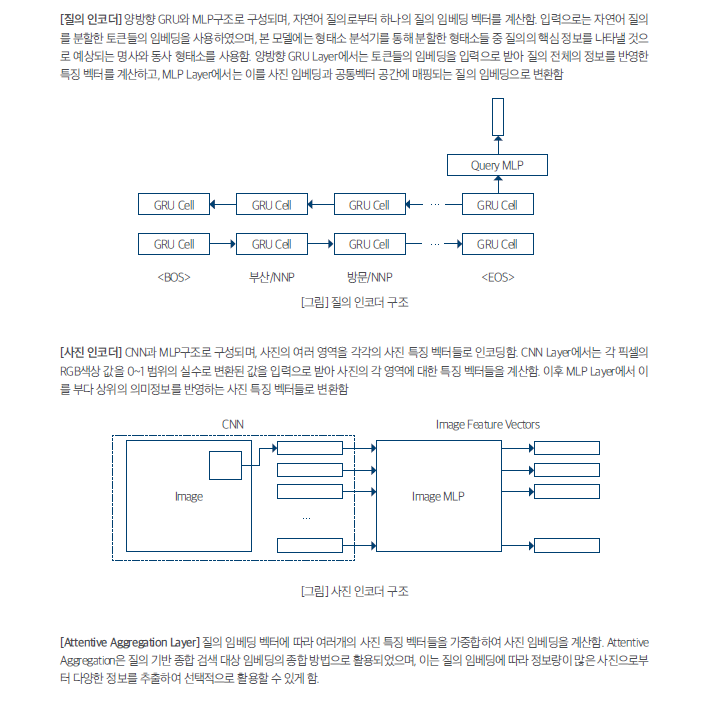
[HT.V0.1.16]Cross modal embedding based on Attentive Aggregation
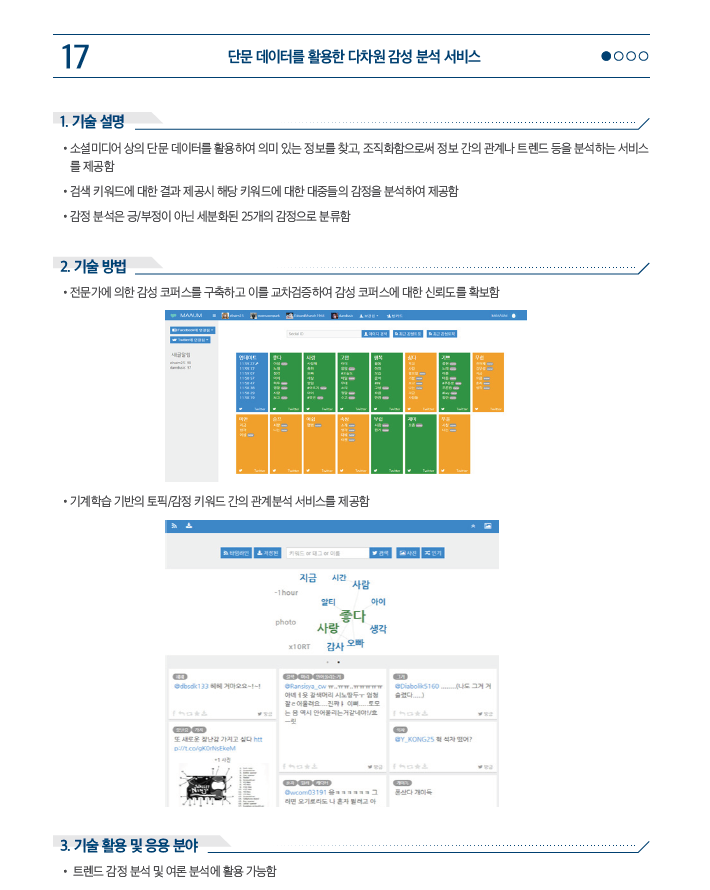
[HT.V0.1.17]Multidimensional sentiment analysis service using short text data
[HT.V0.1.18]Deep learning writing service and application service